When you run vmware-cmd with the -H option pointing to a vCenter Server system, use "--vihost"
to specify the ESXi host to run the command against.
# vmware-cmd -H vCenter_system -U user -P password --vihost ESXi_host /vmfs/volumes/Storage2/testvm/testvm.vmx start soft
Examples:
# vmware-cmd [connection_options] /vmfs/volumes/storage1/pc1/pc1.vmx getstate
# vmware-cmd [connection_options] /vmfs/volumes/storage1/pc1/pc1.vmx start soft
# vmware-cmd [connection_options] /vmfs/volumes/storage1/pc1/pc1.vmx start hard
ESXCLI:
You can run ESXCLI commands as vCLI commands or run them in the ESXi Shell.
# esxcli vm process list ## list machines by name, World Number, UUID, and path to the .vmx.
# esxcli vm process kill --type= [soft,hard,force] --world-id= WorldNumber
# vim-cmd vmsvc/getallvms ## list machines by name, World Number, UUID, and path to the .vmx.
# vim-cmd vmsvc/power.getstate VMID ## get the state of the VM.
# vim-cmd vmsvc/power.shutdown VMID ## shut that particular VM down.
-- just using the linux/freeBSD "like" shell:
# ps | grep vmx ## identify the VM
# kill -9 ProcessID
6.3 KVM
# virsh list ##shows names, id's# virsh shutdown debian1 ##shutdown by name
# virsh shutdown 4 ##shutdown by id
# virsh reboot 3
6.4 Xen
The term "domain" is (sort of) an identifier for the unique space a certain VM runs in.-- stop VM:
# xe vm-shutdown -–force uuid=[UUID for VM] ## use the unique UUID for the VM.
or
# list_domains
# list_domains | grep [UUID] ## get the identifier of the VM
# destroy_domain –domid [id]
-- start VM:
# /opt/xensource/bin/xe vm-reboot -u root vm-name=vm_name
# /opt/xensource/bin/xe vm-reboot -u root vm-id=vm_UUID
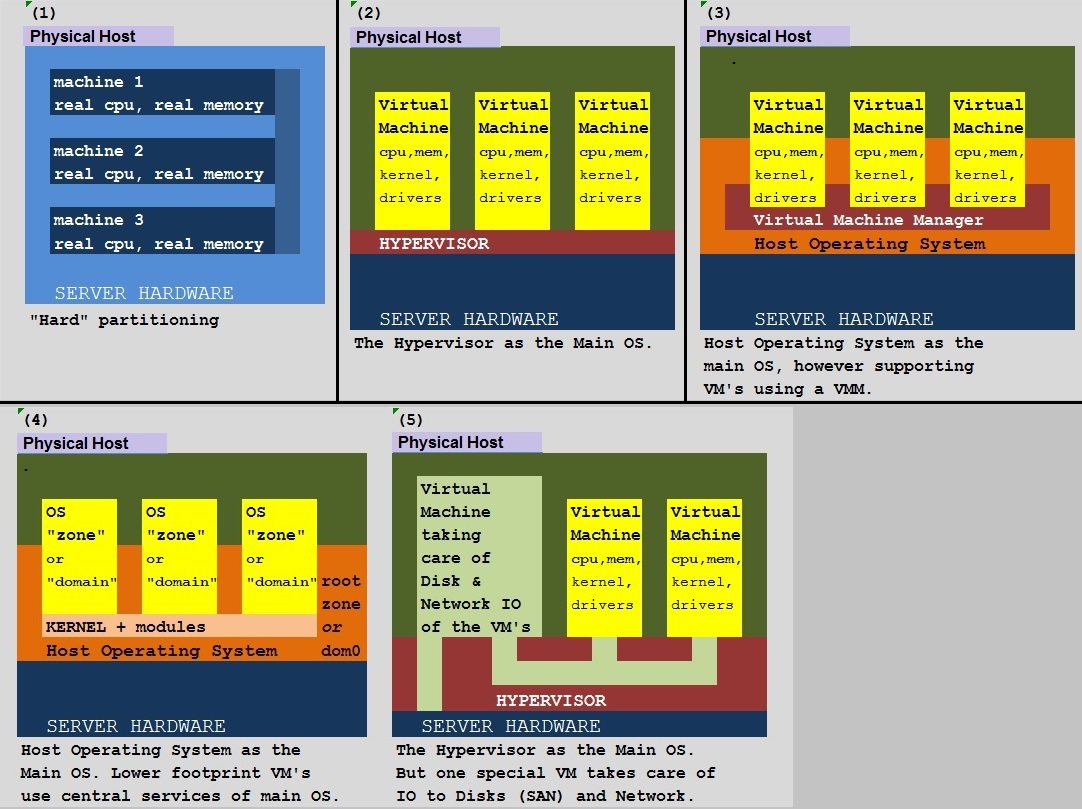
7. IBM Midrange "Power" lPar/wPar.
Figure 10: IBM Midrange virtualization (SystemP, SystemI).
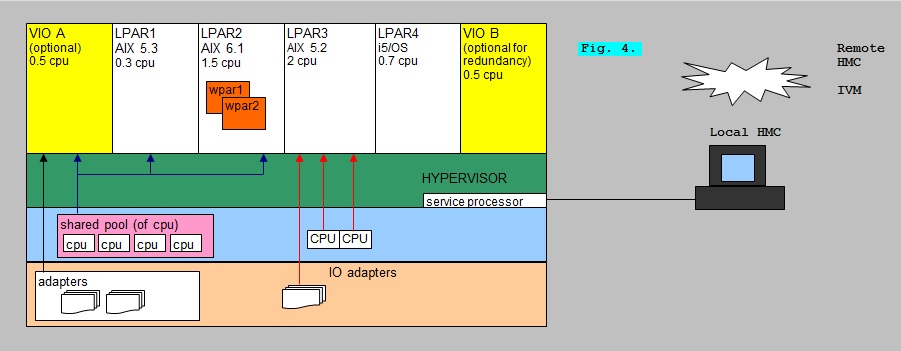
In the figure above, you see a physical Host, which facilitates a number of VM's.
On IBM midrange/mainframe systems, those VM's are called "LPARs" or "Logical Partitions".
On midrange systems, the VM's usually run the AIX (unix) operating system or Linux (modified RedHat, Suse and some others).
The "architecture" of the Hypervisor could be an implementation of (2) or (5) as was shown in figure 1.
It's actually more like (5), if a socalled VIOS is implemented. VIOS is short for "Virtual IO server", and if it's present,
it takes care of all network- and disk IO on behalve of all LPAR client systems.
You can create and modify LPARS using the commandline (pretty awkward), or using a graphical console, the "HMC",
which communicates to the service processor of the physical Host.
Using the HMC, makes it quite easy to create, modify and maintain LPARS, including all actions to assign
virtual resources like adding, or lowering "virtualized cpu" and "virtualized memory" to LPARS.
Usually, a VIOS is implemented, since then the network adapters and diskcontrollers are owned by the VIOS,
which "shares" them among the client adapters.
However, it is still possible that you assign a dedicated network- and or diskcontrollers to an individual LPAR,
but since that's costly, it's seldom done.
Virtualized Resources:
With respect to IO, an LPAR may own netcards and diskcontrollers. But that's uncommon.
More often, a VIOS owns such controllers and expose them to the LPARS.
You may consider the physical memory, and physical cpu-cores of the Host, to be existing in a 'pool'.
From the HMC, processing capacity for a LPAR is specified in terms of "processing units (PU)".
So, for example, you could allocate a LPAR a PU value of (desired) 0.8 (a CPU capacity of "0.8 CPU").
When setting up an LPAR, you can specify a Minimum (min), a Desired (Des), and a Maximum (max) value of PU.
Then, when the Hypervisor is distributing the total workload among the LPARs, a certain LPAR will not dive under the Min value,
and it will not exceed the Max value. Normally, it will operate in the "Desired" value.
The same principle applies with memory too. You can specify a Minimum, a Maximum, and Desired amount of memory
to be assigned to a certain LPAR.
Queries(commands) from the HMC:
Ofcourse, using the graphical screens you can view all sorts of attributes of all LPARS.
The HMC also provides for a commandline, from which you can perform all administrative tasks.
Here are a few examples:
-- listing status LPARS:
hscroot@hmc-op:~> lssyscfg -m P570 -r lpar -F name,lpar_id,state
P570P06,......6,...Running
P570P05,......5,...Running
P570P04,......4,...Running
P570P03,......3,...Not Activated
P570P02,......2,...Running
VIO-ServerA,..1,...Running
-- Shutdown an LPAR:
hscroot@hmc-op:~> chsysstate -r lpar -m P570 -o shutdown -n P570P05
It's a great platform. I worked with those system up until Power6, and AIX 6.1, then I lost track
of such systems since the places I worked later on, did not used it, or I did not performed SysAdmin work.
I keep the overview very limited here. I am pretty amazed, how much still is quite the same up to this day.
If you like to see more, I advice to dive into the IBM redbooks. I have an old document, but much is still usuable, even today.
The silly thing is: it's an Excel document. I don't know "why the hack" I choose Excel, but in some silly way... I did.
If you like to see that (silly) document, then you might use:
Some notes on AIX 5.3 / 6.1 + virtualization (Excel format)
8. MS Hyper-V.
This implementation of Virtualization, is from Microsoft, and fully tied to the Windows platform.It's called "Hyper V". Usually you have a strong physical Host, running Windows Server 2008/2012,
on which you can create and maintain client Virtual Machines.