
From that, browse the columns that are interesting, and adjust your query accordingly, possibly with clauses like
"user_updates>n", or "ORDER BY user_updates" etc..
You really need to play with this view a bit, to appreciate the information you can get.
4.2.4 The "sys.dm_db_index_physical_stats" FUNCTION:
You notice the "physical_stats" in the name of this function? Indeed, this function will reveal to us
how index pages are filled with rows, and what their average fragmentation level is.
4.3 How to move a hotspot index to another Filegroup:
Important:- Make sure you have scripted your objects, that is, have the create scripts of all objects.
- Moving large indexes, cost a lot of performance and will take time. With the Enterprise Edition, theoretically
you can do it "ONLINE", but, for example, you don't want to move a 700 million row index while the users are busy.
Personally, I think that moving objects like tables and indexes to other tablespaces, is quite easy in Oracle.
Ofcouse, the methods exist in SQL Server too, but here it's somewhat more elaborate.
Anyway, if you move an index from one filegroup to another filegroup, there might be a mean rattlesnake in the grass.
Essentially, moving an existing index, means dropping it and then recreating it.
Now, if this index supports some Constraint, like a Primary key, or PK-FK relations, you must enable them again!
It is easy to forget this, because moving an index "looks" like a single action. It is, as long there are no
constraints involved.
Although, trying to explicitly dropping an index (with the DROP INDEX statement) that supports a Primary key, will be denied
by the Database Engine. But, other statements (like ALTER INDEX) will work.
In reality, before you do anything, make sure you script the database. That means that SQL Server will script
all create statements with respect to tables, indexes, constraints, triggers, etc.. etc..
This way, you just have an ascii file with all create statements, and if you need it, you can easily retrieve
for example, an index create statement etc.. without that you need to "remember" which columns were involved. It's easy to do that: just browse around a bit in SQL Server Management Studio (SSMS).
(Just rightclick your database -> choose Tasks -> choose Generate Scripts)
Note: Many professional systems, have some sort of repository, describing all objects, including the TSQL create statements.
Now, how to move an table and or an index to another filegroup?
Let's review in a few simple examples, how indexes are created on an existing table.
Lets make a simple example table:
CREATE TABLE dbo.Customers
(
Cust_id int NOT NULL,
Cust_name varchar(20) NOT NULL,
Address varchar(30),
City varchar(20),
Country varchar(20)
)
ON FG_DATA -- The filegroup FG_DATA for storage of tables
GO
- Clustered:
CREATE CLUSTERED INDEX indx_employee_emp_id ON EMPLOYEE(EMP_ID)
- non-clustered:
CREATE NONCLUSTERED INDEX indx_employee_empname ON EMPLOYEE(EMP_NAME)
ON FG_INDEX -- The filegroup FG_INDEX for storage of non-clustered indexes
Or the Index Create statement in a slightly generalized form:
CREATE [CLUSTERED | NONCLUSTERED] INDEX
Note that I did not use the "ON FG_INDEX" clause with the clustered index create statement.
I could have done that, but that would imply that I "moved" the table to that filegroup.
Again, the table (in simple words) is actually the same as the clustered index.
So, we can immediately conclude the following:
1. How to "move" a table with a clustered index to another filegroup:
DROP the clustered index. Create the Clustered Index again with Filegroup clause pointing to the right filegroup.
2. How to "move" a clustered index to another filegroup:
Ofcourse, it's the same as above.
You cannot move indexes supporting a unique or primary key constraint, using a DROP statement.
As we will see later on, to move these indexes, we must use the CREATE INDEX statement with the (DROP_EXISTING=ON) option.
3. How to "move" a non-clustered index to another filegroup:
DROP the non-clustered index. Create the non-Clustered Index again with Filegroup clause pointing to the right filegroup.
The points 2 and 3 are great, if you would have the original CREATE statements of those indexes.
But there exists another method too. This is by using the "CREATE INDEX .. (DROP_EXISTING=ON).. ON [filegroup_name]" statement
4. Alternative method for "moving" a clustered or non-clustered index to another filegroup:
As a generic example for using the CREATE INDEX .. (DROP_EXISTING=ON) statement, take a look at the following syntax:
CREATE [NON]CLUSTERED INDEX INDEX_NAME
ON TABLE_NAME(column1, column2,...)
WITH DROP_EXISTING
ON [filegroup_name]
If the index enforces a PRIMARY KEY or UNIQUE constraint and the index definition (which columns) is not altered in any way,
the index is dropped and re-created, and will preserve the existing constraint.
If you want a list of Primary, Unique, and Foreign key constraints, you might want to play with the following queries:
select * FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
select * FROM INFORMATION_SCHEMA.CONSTRAINT_TABLE_USAGE
select * FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS
SELECT substring(object_name(constid), 1, 40) AS FK,
substring(object_name(fkeyid), 1, 40) AS "Referencing Table",
substring(object_name(rkeyid), 1, 40) AS "Referenced Table"
FROM sysreferences
ORDER BY object_name(rkeyid)
4.4 Quick check on the effectiveness of your indexes:
In section 4.2.3, we have touched the "sys.dm_db_index_usage_stats" Dynamic Management View.This view shows us many interresting facts like "user_scans", "user_lookups" etc.., so it gives us a good idea
on the usage, or the effectivity, of an index.
- In general, if an index has a relatively high number of "reads", compared to the "writes", that is a clue
that the index is used much. So, it's probaby an effective index.
So, if the "total Reads" > "total Writes", it's a good index.
- Also, if an index has a relatively high number of "writes", compared to the "reads", that is a clue
that the index is NOT used much. So, it's probably an ineffective index.
If there are little reads, but many writes, the system is busy updating the index, without that users are using it.
You know that writes to an index means updating it. Reading an index means that a query is using it.
So, if the "total Writes" > "total Reads", the index only spills performance, and it's not a good index.
Here is a handy query that produces a list of the indexes in a Database, including the Reads from, and writes to, the indexes.
SELECT OBJECT_NAME(s.[object_id]) AS [Table Name], i.name AS [Index Name], i.index_id,
user_updates AS [Total Writes], user_seeks + user_scans + user_lookups AS [Total Reads],
user_updates - (user_seeks + user_scans + user_lookups) AS [Difference]
FROM sys.dm_db_index_usage_stats AS s WITH (NOLOCK)
INNER JOIN sys.indexes AS i WITH (NOLOCK)
ON s.[object_id] = i.[object_id]
AND i.index_id = s.index_id
WHERE OBJECTPROPERTY(s.[object_id],'IsUserTable') = 1
AND s.database_id = DB_ID()
AND user_updates > (user_seeks + user_scans + user_lookups)
AND i.index_id > 1 -- not the heap or clustered indexes
ORDER BY [Difference] DESC, [Total Writes] DESC, [Total Reads] ASC;
Note how this query only uses the "sys.dm_db_index_usage_stats" Dynamic Management View.
4.5 How to Reorganize and Rebuild Indexes:
4.5.1 How to detect Index Fragmentation:Especially, the dynamic management function "sys.dm_db_index_physical_stats" can be of help in determining
if an index is too much fragmented or not.
The function need a number of parameters, which might be left as "null".
The more parameters you specify (as not being "null"), the more specific the output will be.
In particular, there are three very usefull ways to use the function:
(1) Get the details (a list) of the fragmentation levels of all indexes in a certain Database.
(2) Get the details of the fragmentation levels of all indexes of just one specific Table.
(3) Get the details of the fragmentation level of just one specific index of just one specific Table.
Here are a few examples:
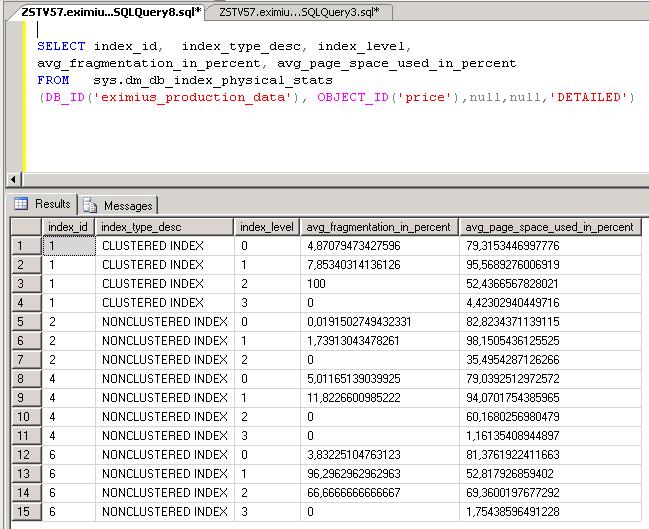
SELECT index_id, avg_fragmentation_in_percent, avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID('SALES'), OBJECT_ID('dbo.EMPLOYEE'),null,null,'DETAILED')
SELECT SUBSTRING(OBJECT_NAME(object_id),1,30) AS NAME, index_id, SUBSTRING(index_type_desc,1,20) AS TYPE,
avg_fragmentation_in_percent, avg_fragment_size_in_pages page_count
FROM sys.dm_db_index_physical_stats(DB_ID(N'SALES'), NULL, NULL, NULL , 'DETAILED')
The first query, shows the fragmentation (column "avg_fragmentation_in_percent") of the indexes of the EMPLOYEE table only.
The second query, shows fragmentation information of all indexes (of all Tables) that exist in the SALES database.
Note that the column "avg_fragmentation_in_percent" in the output, shows you the relevant information.
In section 4.2.4, you can find a real example, with example output, of using this function.
According to Microsoft documents, you should Rebuild indexes when the average fragmentation is higher than, say, 25 to 30%.
You might consider Reorganizing indexes when the average fragmentation is between, say, 15 to 25%.
For the smaller indexes, don't expect high improvements from rebuilding or reorganizing indexes.
For larger indexes, the improvement can be very significant.
4.5.2 How to Reorganize and Rebuild Indexes:
- Reorganizing, defragments only the leaf level of clustered and nonclustered indexes on tables. The same pages are used again.
Since a fill factor can be specified, it's likely that empty pages will result by this "compaction". These are removed, and thus providing additional available disk space.
The fill factor, as the name already implies, specifies "how full" a page should be filled, like for example "70" (70%) or "80" (80%).
- Rebuilding an index actually drops the index and re-creates a new one. Since this action means completely rebuilding a new index,
all levels (leaf level, intermediate levels, root level) are recreated again, and all fragmentation is removed.
In this process, you reclaim disk space, since all pages are build again using the specified "fill factor" setting.
Usually, rebuilding an index is more resource intensive than reorganizing an index.
Reorganizing is automatically done "online", thus while sessions may access the table and index.
Rebuilding can be done online or offline. If done offline, locks will block sessions for the time the index is rebuild.
With the Enterprise Edition, using the "ONLINE=ON" clause, you can rebuild indexes online.
Still, with very large indexes, it's really best to rebuild them during the times of least activity in the Database.
Here are a few examples on how to rebuild or reorganize indexes:
First a warning. You can explicitly DROP an index, and CREATE it again, assuming you had the original CREATE statement.
In most cases, the Database will not execute the statement if the index supports (or "is") a Primary Key or Unique constraint.
But you still must be carefull, in how far the index supports any constraint at all. You have to investigate that first.
So, it's best to NOT to "DROP" and "CREATE" an index, unless you know the details of your constraints.
But, when using the "ALTER INDEX .. REBUILD" and "DBCC DBREINDEX()" commands, you are pretty save.
Thus, you can use two types of commands to Rebuild an Index: the "ALTER INDEX" statement and the "DBCC DBREINDEX()" statement.
The DBCC command is more SQL Server 7/2000 "style", but it's still valid in 2005 and 2008.
Just take a look at the following examples. How to deal with all indexes of all tables in a database, is the subject of the next section.
The examples below are very simplistic. You need to read Books Online (BOL), or search the internet, to find all clauses and options
that you can use with the ALTER INDEX and DBCC REINDEX commands.
ALTER INDEX IDX_Employee_EMPID ON Employee REBUILD -- only rebuild the index "IDX_Employee_EMPID"
ALTER INDEX ALL ON Employee REBUILD -- rebuild all indexes of the EMPLOYEE table
ALTER INDEX IDX_Employee_EMPID ON Employee REBUILD WITH (FILLFACTOR = 80) -- only rebuild the index "IDX_Employee_EMPID" with FILLFACTOR=80
So, "ALTER INDEX ALL Table_Name REBUILD WITH (FILLFACTOR = n)" takes care of all indexes of a certain table.
DBCC DBREINDEX(EMPLOYEE,'',80) -- rebuild all indexes of the EMPLOYEE table with a FILLFACTOR=80
So, "DBCC DBREINDEX(Table_Name,'',Fillfactor)", takes care of all indexes of a certain table.
Question:
Maybe this is a difficult question. It's certainly a very interresting question.
If needed, search Books Online (BOL) and/or the Internet for answers.
Suppose a table has a clustered index, and several non-clustered indexes.
What happens to the non-clustered indexes, if you rebuild the clustered index?
4.5.3 How to "dynamically" generate index rebuild statements of all indexes in a Database:
If you want to "dynamically" generate the rebuild statements for all usertables in a Database,
we can use a looping construct, called a cursor.
-- A loop generating DBCC statements:
set nocount on
DECLARE @TableName varchar(255)
DECLARE TableCursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_type = 'base table'
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT 'DBCC DBREINDEX('+@TableName+','+''''',80)' -- asssuming a fill factor of 80
FETCH NEXT FROM TableCursor INTO @TableName
END
CLOSE TableCursor
DEALLOCATE TableCursor
-- A loop generating ALTER INDEX statements:
set nocount on
DECLARE @TableName varchar(255)
DECLARE TableCursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_type = 'base table'
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT 'ALTER INDEX ALL ON '+@TableName+' REBUILD WITH (FILLFACTOR=80)'
FETCH NEXT FROM TableCursor INTO @TableName
END
CLOSE TableCursor
DEALLOCATE TableCursor
Chapter 5. How to determine if you have too low CPU power.
Again, just like in chapter 1, System Monitor (or Performance Monitor), and the dynamic management views (dmv's) can learn us a lot.It's important to differentiate here, between a "real cpu problem", meaning that for the workload,
you just have too little CPU power. But it can be a bit confusing, because it can also be that you only have an "apparent cpu problem",
because of waits of some sort.
Let's first take a look at what we can discover using Performance Monitor (perfmon).
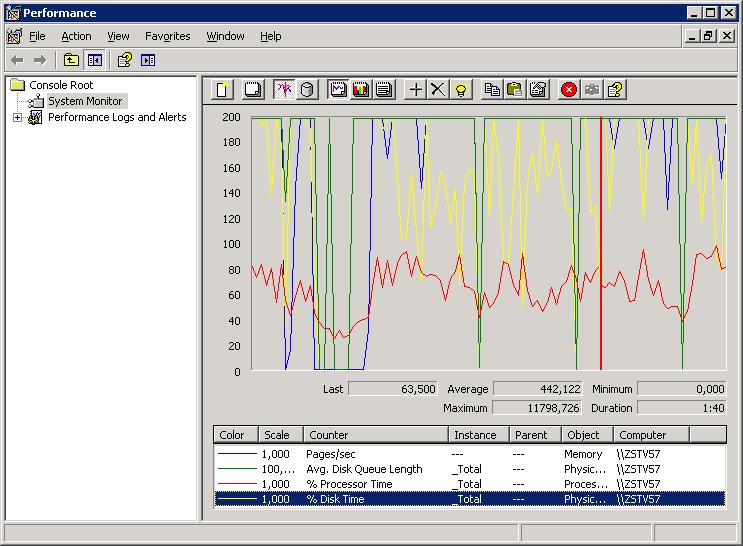
5.1 Taking a quick look Using Perfmon:
This is going to be a bit of a trivial section, I am afraid.One other very important counter, is not found under the "Processor" object. Instead, select the "System" object, and select
the "System\Processor Queue Length" counter.
Please see section 1.2 for a short explanation on "objects", "counters", and "instances".
There are ofcourse many other interresting counters like "%DPC Time" etc.., but these are not that "relevant" for "our quick look".
A short description of the above counters is:
- %Idle Time: Shows the %time that the processor(s) was idle during the sample interval.
- %Priviledge Time: Shows the %time that the processor(s) was running Kernel Mode code during the sample interval.
- %User Time: Shows the %time that the processor(s) was running User Mode code (non kernel) during the sample interval.
- %Processor Time: Is almost the same as (%Priviledge Time + %User Time).
- Processor Queue Length: This indicates the number of threads in the processor queue. It may be considered to be "high",
if on average it's much more than 2 x #cpu's in your system.
With all those counters, some occasional "spikes" are no big deal. Only if you see structural high values (except for "Idle Time"),
on average, or for a considerable amount of time (say, during a "batch"), you might have a cpu botlleneck.
1. One very trivial remark is this: if the "Processor:Idle Time(_Total)" is very high most of the time, you do not have
a CPU pressure at all on your system. Or, what is the same, if %Processor Time is low most of the time,
you do not have a CPU pressure on your system.
2. If on average, you system shows about 40, 50, 60 %Processor time, I would say it's nicely at work.
Because, suppose that the cpu's were idle all the time, then that's not good either. It would be a waste of cpu power.
3. Now, what if the cpu's show a %Processor time which hovers around 90% most of the time? That should certainly get our attention.
One of the most important questions following point 3) is, is it really a CPU bottleneck, or are those observations
also caused by "some deeper technical reason"?
4. If the cpu's show a "%Processor time" which is high most of the time and "Processor Queue Length" is considerably large too,
then you have a strong indication of a structural CPU pressure.
Although it all seems "obvious", do no jump to conclusions yet.
I think that after reading the material in chapter 9, we will appreciate that statement somewhat more.
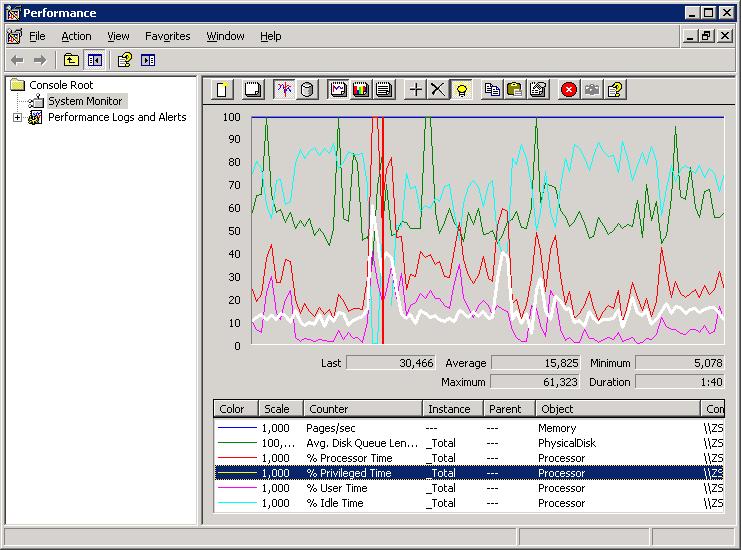
If you use perfmon and measure the above metrics for a representable amount of time, and you indeed find
high values on average, it's quite likely you have a bottleneck "somewhere". And indeed, it's likely to be the cpu's.
But what to think of this example. Suppose you have a Database Server, and a number of application Servers.
When some large batch starts, many application components on the Application Servers, all starts tasks on the
Database Server at the same time, and all keeps running until the batch finishes. Maybe thats why we see such a high cpu pressure.
It could be true that this is "as designed", and we are too low on cpu power. Or something else is not right.
We always need a helicopter view so to speak, on the system as a whole.
So, it's often too difficult to reach well founded conclusions, using Performance Monitor alone.
That's why you also need other information, and at least take a look at the dynamic management views as well.
5.2 Using some dynamic management views:
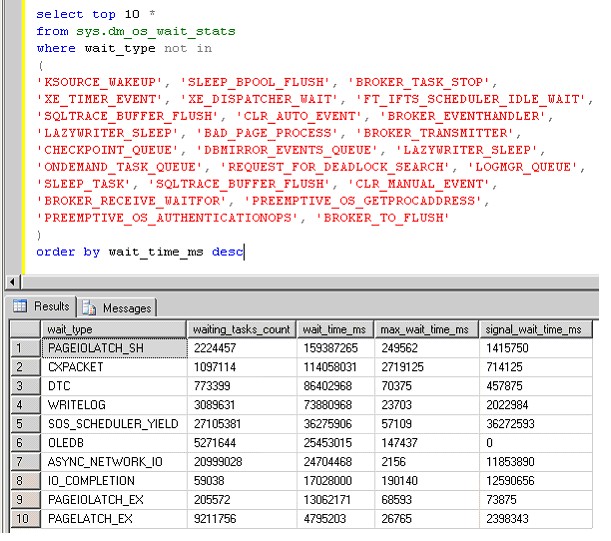
Again, the DMV "sys.dm_os_wait_stats" can give us valuable pointers to existence of possible "CPU pressure".When a session is "ready for some work", it will first enter the "runnable queue". The longer this queue is,
the more we may presume that cpu pressure is actually really true, since a longer queue length implies that
the cpu cannot keep up sufficiently with the demands.
As a session does work, but then have to wait on some "resource" (like pages that must be fetched from disk),
it will be put in a "waiters queue", until conditions have arived that makes it runnable again (put in the runnable queue).
The time waiting in the runnable queue for CPU, is shown as "Signal Waits".
The time waiting for a resource is shown as "Resource Waits".
The following query will show you a grand total of the percentage of Signal Waits and Resource waits,
and thus allows us to compare the two.
If the total of "%signal waits" is highest, it's a reasonable pointer to suspect CPU pressure.
If the total of "%Resource waits is highest, it's a reasonable pointer to suspect overall poor IO, or excessive locking behaviour.
Again, to draw conclusions on this alone, is not a good idea ! Also take a look at section 5.1.
Select signal_wait_time_ms=sum(signal_wait_time_ms)
,'%signal (cpu) waits' = cast(100.0 * sum(signal_wait_time_ms) / sum (wait_time_ms) as numeric(20,2))
,resource_wait_time_ms=sum(wait_time_ms - signal_wait_time_ms)
,'%resource waits'= cast(100.0 * sum(wait_time_ms - signal_wait_time_ms) / sum (wait_time_ms) as numeric(20,2))
From sys.dm_os_wait_stats
select top 20
st.objectid, st.dbid,
total_worker_time/execution_count AS AverageCPUTime,
CASE statement_end_offset
WHEN -1 THEN st.text
ELSE SUBSTRING(st.text,statement_start_offset/2,statement_end_offset/2)
END AS StatementText
from
sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
ORDER BY AverageCPUTime DESC
This section is not ready yet. I am thinking on what to present in chapter 9, probably finish that first,
and then return to this section.
So please continue with the other chapters. Thanks !
Chapter 6. Allocation Unit and Partition Alignment.
If you are involved in a new project, designing an architecture for a large and/or very active database,the design/implementation of storage for your database is very important.
You always should seperate tabledata (or clustered indexes), and non-clustered indexes,
and the files of the transactionlog (and tempdb also), on different filesystems (E:, F:, G: etc..) on different
diskvolumes (actually, different independent spindels).
This is to ensure performance. At the same time, you need a High Availabily solution for your database files,
like some RAID implementations.
I presume that the upper is know to you. In chapter 7, we are going to deal with that subject.
In this chapter however, we mean something different: here we are going to spend a few words on the "allocation unit"
and "partition alignment". This subject is not too exiting, and don't expect miracles from it.
In the following, we will make a certain abstraction. Be warned though: for your specific types of storage, the following
maybe does not apply at all! That's why you need to talk with people who understand your type of storage.
Allocation Unit:
Disk sectors are almost always 512 bytes in size. The allocation unit, or blocksize on disk (not the SQL server blocksize!)
is determined when you format the disk. Here, you often can choose values like 2K, 4K, 16K, 32K, 64K, and sometimes even larger.
Now, the question may arise: is there an optimal allocation unit for SQL Server?
The fundamental pagesize in SQL server is 8K. Secondly, SQL Server often 'read ahead' in 64K 'chunks' (extends).
Two things here:
This question relates to the RAID implementation you have choosen, like RAID5 or RAID10.
In this case, under the hood, the chosen stripesize is of importance, and determines what you should
should take as a suitable allocation unit.
1. If you use such a RAID implementation, first the choosen "stripe size" is important. Many articles suggest you should
use a "n x 64K" stripe size (like 64K, 128K, 256K).
2. After the RAIDn unit is available and viewable as "a disk" in Windows, you partition and format it. Now, what allocation unit should you choose? This is very a hard question to answer.
So?
Microsoft articles seem to suggest that it's always best to choose an 64K allocation unit.
That might be true. Surely, SQL server is their product, so they should know.
Several other articles studied the performance (in general) using 64K and 128K stripe sets, in combination
with 4K, 8K and 64K allocation units. The results varies a lot, so IMHO, we cannot easily answer the question!
It all depends on storage, type of RAID, stripeset choosen, type of database etc..
In most cases, if we are talking about a very ordered Dataware House, with almost only reads and
very neat rebuild tables/indexes, I would also choose 64K allocation unit.
So? I am afraid I was not able to fully answer the question of the "best allocation unit".
Hopefully you agree that's simply not easy to answer unless you know a lot of details.
But generally speaking, I would also say that an allocation unit of 64K seem right, since SQL server
for table and index data 'thinks' in 64K chunks (extents) anyway.
Partition Alignment:
Many articles which discuss "partition alignment", speak of a possible "overall" performance increase of about 15%-30%.
So, if you do this "right", it could have a significant effect.
This work is or should typically be done by a storage admin, or sysadmin, who installs a Server and implements the disksubsystem.
Maybe first you should check with those people, to get the facts (for your specific storage) straight.
In the unlikely case they answer with "huh..?", then you have to provide the neccessary input.
Partition alignment, (or volume alignment, or sector alignment as it is called occasionally) has "something to do"
that the offset of the start of the partition, from the very beginning of the disk, should align with the stripset
that is in effect on your RAID system.
If this not the case, more IO is done than is strictly neccessary.
Now, the point is, the Vendor of your diskarry, or the person who installs it, should know these "magic" numbers.
In practice however, if the information is not available, there are generic setups that seem to work.
If you setup partitions under Win2K8, you will not be "bothered" by the misaligned offset. This system will take care of it.
But, on Win2K3, it could be an issue.
Anyway, if on Win2K3, a 64K offset (128 sectors) is a common value that works on many storage arrays.
Win2K8 uses a 1024K offset, which should work even better.
So, we will take that as our preffered offset.
How to do it yourself? The tools you could use are "diskpar" or "diskpart".
However, DiskPart.exe is the preferred method since it's newer and is included as of Win2K3 sp1.
DISKPART> list disk
shows a list of your disks...
Now, suppose you want to align and then format disk 3:
DISKPART> select disk 3
Disk 3 is now the selected disk.
DISKPART> create partition primary align=1024
DiskPart succeeded in creating the specified partition.
DISKPART> assign letter=F
DiskPart successfully assigned the drive letter or mount point.
DISKPART> format fs=ntfs unit=64K label="SQLINDEX"
Note that in the above example, I choose for align=1024, which is 1MB or 2048 sectors.
It's very likely that this boundary will match most stripe units.
After the formatting is done, you can check the offset using the "wmic" command, like so:
C:\> wmic partition get BlockSize, StartingOffset, Name, Index
There are so many more considerations on storage. For example, a feature like "HBA queue length" is important as well.
So, in general, I would say that DBA's just need storage specialists for large projects.
But at least it's good to know that the right choices on "allocation unit" and "partition alignment" could play
"some" role as well in "overall" performance.
Chapter 7. Placement of objects on Filegroups.
7.1 The "traditional" non-partitioning approach:
If you are not too familiar with the concept of "filegroups", here is a small demo.In the example below, we are going to create the database "SALES", and instead of just having
only the PRIMARY filegroup (the default), we make two additional "logical containers": SALESDATA01 and SALESINDEX01.
A filegroup can contain one or more files (usually more than one, if we have a large database).
The "trick" is, to let the files of a certain filegroup, reside on another filesystem,
than the files of the other filegroups.
If those filesystems correspond to really different diskvolumes, we can achieve parallel IO.
This is so, because when you create a Table or an Index, you can specify (as a clause), on which
filegroup it is supposed to live.
Or, with existing tables and indexes, it's possible to move tables, and non-clustererd indexes, to their own filegroups.
So, filegroups make it possible to seperate tables and indexes, and nothing prevents you from further
seperate large tables (or indexes) on their own filegroups (just create the appropriate number of filegroups).
create database SALES
on PRIMARY
(
name='SALES',
filename='f:\mssql\dATA\SALES.mdf'
, size=400MB,
filegrowth= 0MB,
maxsize= 400MB
),
FILEGROUP SALESDATA01
(
name='SALES_DATA_01',
filename='g:\mssql\data\SALES_DATA_01.ndf',
size= 4000MB,
filegrowth= 100MB,
maxsize= 8000MB
),
FILEGROUP SALESINDEX01
(
name='SALES_INDEX_01',
filename='h:\mssql\data\SALES_INDEX_01.ndf',
size= 4000MB,
filegrowth= 100MB,
maxsize= 8000MB
)
LOG ON
(
name='SALES_LOG_001',
filename='i:\mssql\log\SALES_LOG_001.ldf',
size= 3000MB,
filegrowth= 100MB,
maxsize= 8000MB
)
ALTER DATABASE SALES
MODIFY FILEGROUP SALESDATA01 DEFAULT
GO
In the above example, you see that I only have F:, G:, and H: for filegroups for tables and indexes.
It's very important to put the "transactionlog file(s)" seperate from the above filesystems for tables and indexes.
In the above example, the transactionlog resides on I:
Approach 1:
As you have seen from chapter 4, if a table has a clustered index, in effect, the leafpages of that clustered index
are the tablepages theselves.
So, if all (or most) of your tables have a Primary Key (and are enforced by the unique clustered index), then you could follow this approach:
Create nonclustered indexes on a filegroup other than the filegroup of the table (= clustered index).
And repeat that approach for all other relevant large and/or active tables.
Ofcourse, you cannot give every non-clustered index it's own filegroup, so probably you will put a fairly large number
of indexes on "filegroupA", and possibly another fairly large number of indexes on "filegroupB".
This is all actually no more than "common sense".
You can even apply this approach for the largest and most active tables. Even if your database has hundreds, or even thousents
of tables, I am sure, that using the queries from chapter 4, you will discover that only 10, or 20 or maybe 30, really large
and/or active tables are present. Suppose you have found tables A,B,C,D,E,F,G,H to be very large.
Now, nothing prevents you from placing Tables A, B, C, D on filegroup "FG_ABCD", and place the tables E, F, G, H on filegroup "FG_EFGH".
As a small bonus, having the non-clustered indexes on their seperate filegroup(s), you have some level of additional protection.
If the drive(s) containing those filegroup(s) go bad, or something else crashes, you can regenerated the non-clustered indexes again.
Only the tables (or the clustered indexes) contain the "true" data. All other indexes can be re-created, although it could
take quite some time.
Note: always have a recent database script with create statements of all tables, indexes and all other objects !
Approach 2:
Approach number 1, is most appealing to me. But some DBA's do something else. They just mix tables and non-clustered indexes
among a number of filegroups on different diskdrives. That's not a bad idea either.
It's evident, that here, you are most sure that all diskdrives are used at all times.
You only need to create a list of the largest and/or most active tables and indexes, and distribute those object
on several filegroups (which themselves should reside on different "spindels").
If you want to see which clustered and non_clustered indexes reside on which filegroups, you might use this query:
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O ON I.[object_id] = O.[object_id]
GO
If you do not want to 'see' the systemviews (starting their name often with 'sys') in the output,
then use:
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O ON I.[object_id] = O.[object_id]
WHERE O.Name not like 'sys%'
GO
7.2 Partitioning large tables and indexes:
Here is some extremely short, and lightweight, information on table and index partitioning.
In this section, we go one step further, by "partitioning" subsets of the same one table, on their own filegroups.
Now let that sink in: we will devide a table, into parts, and put those parts on different filegroups. Essentially,
that's partitioning !
Ideally, you would have a certain column in your table, that lends itself easily to "get partioned". In other words,
that particular column would have values that are easily divided into subsets, like for example "years".
For example, you might have a table with some date column, and you could group records belonging to
to the years "2000", "2001, "2002" etc..
But even if it doesn't go in such a "natural way", you can always force some form of subsetting. For example, you have
a nummeric column, and you just are going to distinquish the following subsets:
1 - 10000000
10000001 - 20000000
20000001 - 30000000
etc..
Creating a partitioned Table, or Index, is a 3 step process.
Don't forget that the whole idea behind partitioning a table is this: create Ranges of values, where the rows of the table will
fall into, and make sure that you can store those different record subsets (the different Ranges), onto separate Filegroups.
- We start by defining a Partition Function. This is function that defines the boundaries, or Partition Ranges, that the subsets of rows will use.
- Secondly, we create a Partitioning Scheme, that defines the mappings of the Partition Ranges to FileGroups (individual storage structures)
- Thirdly, we create a Table, using the definitions above.
That's all.
So, a simple example will illustrate this.
1. Suppose we have a certain database, which uses the filegroups FG1, FG2, FG3 and FG4.
Suppose we have a table PARTSAMPLE that we want to partition. It uses the columns ID (datatype INT) and NAME (varchar(20)).
The values that ID can take, are for example 1…1000… 7000… 20000… 30000 etc..
2. Now let's define the "Partition Ranges", or boundaries, that the subsets of rows can take:
We do that by creating a Partition Function, whereas later we are going to "bind" it somehow to the table.
CREATE PARTITION FUNCTION samplefunction (INT)
AS
RANGE LEFT FOR VALUES (10000, 20000, 30000)
GO
This function, is an independent object in the database. Later we will use it in the PARTSAMPLE table definition.
The "LEFT" or "RIGHT" in the function definition means if you want the interval to "leftsided" or "rightsided" as in:
10001 - 20000
10000 - 19999
3. Next, we will define the "Partition Scheme", that will relate the Ranges to the Filegroups:
CREATE PARTITON SCHEME samplescheme
AS
PARTITION samplefunction TO
([FG1], [FG2], [FG3], [FG4])
GO
You see that in the Partition Scheme definition, we relate the FileGroups to the "samplefunction" function, thus thereby
relating the FileGroups to the Ranges (or boundaries).
4. As the last step, we will define our PARTSAMPLE table, using the Partition Scheme defined above.
CREATE TABLE PARTSAMPLE
(
ID INT NOT NULL,
NAME VARCHAR(20) NOT NULL
)
ON samplescheme(ID)
GO
So, if a record with an ID of 15000 would be inserted, it would be stored on FileGroup "FG2".
Likewise, if a record with an ID of 25000 would be inserted, it would be stored on FileGroup "FG3".
Chapter 8. Other remarks on several subjects.
In this chapter, we will review a couple of other important subjects.
8.1 The right choice of datatypes.
SQL Server knows a huge number of datatypes. If you define a table, you tell SQL Server the columnnames,and the datatypes (and possibly other attributes as well).
For example, we have the datatypes "int" (integer), "decimal(n,m)", "char(n)", "varchar(n)", "datetime" etc..
If you create the tables yourself for some application, or you are able to advise a developer, the following is
quite important.
If you choose "too wide" datatypes, you fill a database block "too quickly". This means that a smaller number of rows
fits in a table page.
This cost performance, because the database needs to read more pages, to get the same imformation.
For example, suppose some table has a "COMMENT" column. Think of the consequence if some developer choose a
a datatype of "char(2000)", meaning a fixed column lenght of 2000 bytes.
Now if the comment is at most just a few words, then that's a true waste.
So, always try to choose a datatype (with a "width") that suits the purpose, but also not "that thight".
Just try to balance it a bit.
The choice a datatypes also infuences the amount of "processor time".
If you think about a very active database, the first thing that comes to mind, is heavy Disk IO.
But certainly not in all cases. High cpu utilization is a very important performance issue too.
Now, dont think that this will only happen at the physics department, where difficult calculations are used.
Don't underestimate financial applications, where quite elaborate calculations may be done on all sorts of assets
and securities etc..
Here too, the choice of the most optimal datatypes is important. It's difficult to say in general which dataypes
are the best. Just depends on the application. Hopefully, the developers are aware of this fact. Not all are, so I have noticed.
8.2 Some remarks on TEMPDB.
TEMPDB is a sort of "scratch workplace" for SQL Server. You might find many temporay tables here, which might beused for all kinds of sorts, or as a sort of intermediate storage containers, during processing.
A bottleneck in tempdb IO, can impact the overall throughput of your SQL Server.
How active TEMPDB will be, depends on SQL Server itself, and the application.
Usually, the application is the most important factor. But, if for example, SQL Server "versioning" is in use,
then usage on TEMPDB can be very high.
Fortunately, Windows System Monitor (called Performance Monitor in the past) has the neccessary counters
to make a judgement on how active TEMPD actually is.
You can also write your own system queries that gives info on the activity on TEMPDB.
Here are a few examples:
The following will give an idea on allocated pages per session:
USE TEMPDB
SELECT top 10 *
FROM sys.dm_db_session_space_usage
ORDER BY (user_objects_alloc_page_count + internal_objects_alloc_page_count) DESC
The following will give an idea on the number of temporary tables (which name starts with "#")
USE TEMPDB
select name, create_date, modify_date from sys.all_objects
where name like '%#%'
A keypoint is this: if TEMPDB is very active, here too you might coinsider to place the TEMPDB data- and log files
on a fast disk which was not much used before.
Although many of us don't have that luxury, you might consider to place the files at for example a backup dump
disk, which might only be used "occasionally" (once a day, or once an hour, for full- or transaction backups).
Ofcourse, in some cases, that's not a good idea. Only you can determine how matters are in your situation.
A recommendation you can find in many articles, is to let TEMPDB consist of several datafiles.
Some even recommend, that you let the number of files to be equal to the number of cpu cores.
Here is a sample on how you could modify the TEMPDB database:
ALTER DATABASE TEMPDB
MODIFY FILE
(NAME = tempdev,
SIZE = 10MB, -- keep this one small
MAXSIZE=10MB);
GO
ALTER DATABASE TEMPDB ADD FILE ( -- let's add 4 datafiles
NAME = TempDevA,
FILENAME = 'M:\mssql\data\tempdeva.ndf',
SIZE = 100MB,
MAXSIZE = 200MB,
FILEGROWTH = 20MB),
(
NAME = TempDevB,
FILENAME = 'M:\mssql\data\tempdevb.ndf',
SIZE = 100MB,
MAXSIZE = 200MB,
FILEGROWTH = 20MB),
(
NAME = TempDevC,
FILENAME = 'M:\mssql\data\tempdevc.ndf',
SIZE = 100MB,
MAXSIZE = 200MB, FILEGROWTH = 20MB),
(
NAME = TempDevD,
FILENAME = 'M:\mssql\data\tempdevd.ndf',
SIZE = 100MB,
MAXSIZE = 200MB,
FILEGROWTH = 20MB)
GO
8.3 Carefully consider the Max memory limit for SQL Server 64bit.
Suppose you use SQL Server 2005/2008 64. What should be the maximum memory you should assign to SQL Server?Actually, this looks easy, but it isn't.
Suppose your x64 system has only 16GB of memory. Now, NT (meaning Win2k3, Win2k8 etc..) and all sysadmin programs
(like backup software, anti-virus, monitoring agents etc..) needs memory too, which can be considerable.
Because... you don't want that the system exhibits excessive paging.
There is no good alternative other than to discuss this with your nearest senior sysadmin.
So, in the upper example of a system of only 16GB, I suggest you limit it to 12GB.
Just a few words on NT paging.
Using Performance Monitor counters to "measure" the amount of paging, can sometimes be a bit confusing.
If you see a moderate or high value of "Memory: Pages/sec", it does not neccesarily need all to be caused by paging alone,
or pages from and to cache.
Some applications or tools might "page" to memory mapped files, which will "distort" the view considerably.
Besides that, many causes exist why "Memory: Pages/sec" produce high values. But anyway, it should not be too high ofcourse.
You might have high amount of paging, if you see:
"Memory: Pages/sec" - moderate to high.
"Memory: Available Bytes" - would be low.
"Paging File: % Usage" - would be high.
"Paging File: % Peak Usage" - would be high.
"Memory: Pages Output/Sec" - would be high.
This last counter shows how many virtual memory pages were written to the pagefile to free RAM page frames,
and is therefore a good indicator.
It's true that NT will always page to a certain extent.
Especially, with all monitoring "tools" loaded, NT systems will certainly page somewhat.
As to the size of the pagefile, as a rule of thumb for "low" memory systems, it should be around 1.5xTotal RAM.
Ofcourse, the more memory you have, the less important the size of the pagefile is.
No sysadmin will ever create a pagefile of 128GB, if the system has 64GB RAM.
8.4 Commit limits and remote logging of Batches.
What I have seen occasionally, are two sort of "misconfigurations" that can affect performance in a negative way.Most applications, will have some sort of batch facility, which is likely to be scheduled after working hours.
The architecture of such batches, is very diverse.
What can be worthwile, is to investigate if some "component" does "logging" (to a logfile) at a remote host.
If in such a case, a sort of "SEND - Acknowledge" scheme is in use, that can slow down the batch significantly.
Also, it can be worthwile if the "metadata" (in configfiles, or in the registry etc..) of the application, uses
some sort of "commit limit". What I mean is this. Such an application generates smaller or larger batches of transactions.
Each of these batches is comitted. But what is the lenght? Is such a batch 1, 10, 1000, 10000 records "wide"? In the extreme, if a "batch" is only 1 "wide", that too can slow down the batch significantly.
Chapter 9. Some real world cases, describing somewhat more complex performance problems.
9.1 Some important (not so trivial) wait_types:
In this note, we have seen a few subjects that might be the origin for performance problems.As said right from the start of this note, we do not cover Query Design.
Actually, this is one of the most common causes of low performance. Indeed, the impact can be quite severe.
Now suppose you have, what seems to be, a well configured system. So, you have sufficient memory, and Disk IO seems to be fine,
lots of cpu power etc.. etc..
Still you might encounter what appears to be "performance issues".
Here are a few important wait_types to watch for:
CXPACKET: Probably related to "Parallelism".
SOS_SCHEDULER_YIELD: Might be an indicator of CPU pressure.
ASYNC_NETWORK_IO: Might be an indicator of poor Network I/O.
LCK_X, LCK_M_U, & LCK_M_X: Long lasting locks, and/or locks that involve many extents (leading to blocking).
PAGEIOLATCH_X: Buffer I/O latch, maybe due to poor Disk IO, or low on memory.
ASYNC_IO_COMPLETION & IO_COMPLETION: Could also be attributed to poor Disk IO, or general IO issues.
PAGELATCH_X: Buffer latch problems.
WRITELOG & LOGBUFFER: Might be due to poor IO to the Tranaction log disk subsystem.
In the next sections we will some examples of these wait_types.
9.2 LCK_M_U, CXPACKET, SOS_SCHEDULER_YIELD, DTC
Problem: you see high "wait times" associated with one or more of the "wait_types" LCK_M_U, CXPACKET, SOS_SCHEDULER_YIELD,and possibly also DTC. Secondly, you might (but not neccessarily so) find a lot of dealocks in some application log, and/or users complains
that their frontend applications often "stalls".
We know that "under the hood" systems like SQL Server, are incredably complex. But, SQL Server 2005/2008 generates
a lot of tracing or logging "material", which you can "see" using the "dynamic mamagement views (DMV's)".
Although you may not call it "tracing material", the DMV's sure functions that way.
The "keywords" in the title of this section, look pretty impressive. Actually, these are "wait_types".
If you switch back quicly to section 1.3, you find a nice query giving you a top 10 "wait times"
and telling you what "wait types" they are associated with.
Note from the figure in section 1.3, that the "waittimes" due to "wait_type=CXPACKET" are pretty high too.
The wait_types CXPACKET, SOS_SCHEDULER_YIELD, LCK_M_U are in many cases, related to each other.
CXPACKET
CXPACKET waits may indicate parallelism problems. This basically means you are running a parallel process and one
or more threads of it, are waiting for others to complete. CXPackets occur when a query has its operations run in parallel,
but not all operations complete at the same time. SQL Server cannot continue to the next SQL statement
because not all operations have completed. This results in waiting defined as CXPacket.
The setting that determines if "parallelism" is "switched on", is "Maximum Degree of Parallelism" or MAXDOP.
If you rightclick the server object in SQL Server Management Studio, you can view and modify all sorts of settings.
In the "Advanced" page, you will find the "Maximum Degree of Parallelism" setting. If you put it to "1"
you have it switched "off", although TSQL statements can override it with the MAXDOP clause.
Ofcourse, different sessions all operate, and stay to operate, in "parallel", but the parallelism of one statement is off.
If the MAXDOP setting was, for example, "8", you might lower the value, and see what the result is.
Unfortunately, tackling CXPACKET waits usually means a lot of testing (trial and error)
LCK_M_U
Actually, there are many "LCK_M*" wait-types, like:
Lck_M_U is associated to update locks, that might cause other processes to wait, and
Lck_M_X is associated to exclusive locks, which too might cause other processes to wait.
The LCK_M_U wait_type might be found in many cases. It occurs when a task is waiting to acquire an Update lock, which it can't
do at that time, because another process already has aquired a lock of some kind.
-> Possible causes and some guidelines to what to do:
A possible cause to high values of CXPACKET and LCK_M_U might be threads of an application that are frequently waiting on each other.
In this case, it might be due to ineffective "application design".
If you also see considerable "DTC" waits. them that might be a clue that distributed transactions are not
effectively doing their work.
In this case too, it might be due to ineffective "application design".
Knowing the internals of MSDTC and distributed transactions and application design, is a complex world of it's own.
If you have a system with many cpu's, it could even be counterproductive at some batches or statements which are allowed
to use parallelism. It might thus help to reduce the MAXDOP setting, as explained above.
Ofcourse, having many cpu's is very good for overall throughput, and independent sessions are then running
in parallel.
But, with some particular queries, they might use parallelism that might give rise to LCK_M* and CXPACKET waittimes.
Sometimes, using the SNAPSHOT Isolation Level with the option "ALLOW_SNAPSHOT_ISOLATION" set to ON at the database level,
might improve performance.
9.3 Isolation Levels.
Chapter 10: A few good links to technical articless:
-> If you want more depth on SQL Server performance discussions, here is a good Microsoft article:
Microsoft Technet article
-> Great link with good queries:
glennberrysqlperformance.spaces.live.com
-> If you want more depth on SQL Server disk storage design considerations, here is a good link:
Microsoft Technet article
-> If you want more depth on the specifics on TEMPDB, here is a good link:
Microsoft Technet article
-> Some general performance papers:
Top 10 SQL Server performance issues in DW
Top 10 SQL Server performance issues in OLTP
Note: There are some other docs from myself too (excel files):
Listing of some SQL Server 2005 facts & structures (for exam 070-431, 5.5 MB)
Listing of some SQL Server 2008 facts & structures (for exam 070-432, 9 MB)
That's it. Hope it was of any help.