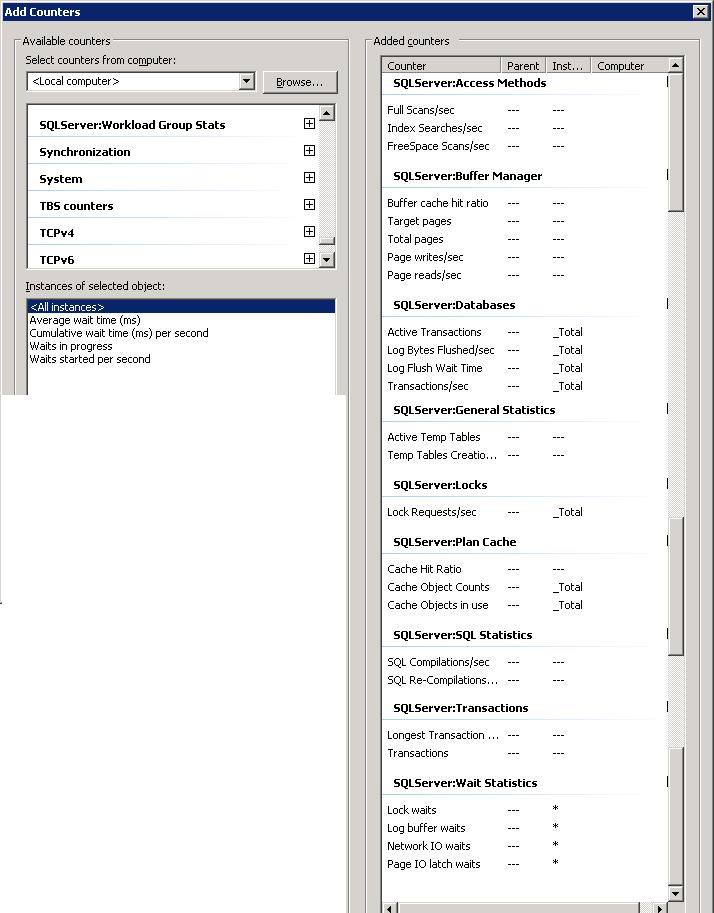
There are literally hundreds of other counters. But the selection above seems to be a "reasonable" one.
10. A few trivial notes on Systems and Hardware.
Here are a few really trivial remarks (sorry):SAN's:
If your database files are on LUNs on a SAN, you generally have not much control on how your filegroups are located on
different "sets of spindels". You know that "spreading" your filegroups over different disks, increase the iops
and generally a better performance might be expected. However, with most modern SANs, its already a fact that
a "volume" is generally created "over a set of n disks".
But it can't hurt to ask your SAN admin about the state of affairs.
Still, it's very important to get one or more extra LUNs in order to seperate the Transaction logs from the database files.
If needed, the same might be true for TEMPDB.
Admins are the finest people around, but be carefull that they don't say to you: "Hi DBA! Here is one fine LUN for you to store your databases."
If you have databases with high workloads, you really need high iops, so, that means a sufficient no of LUNs.
IO and IO Cards to SAN's:
An FC card, or net card (for iSCSI) that connects your system to a SAN, might be a virtualized device (in case of VM's)
or it might be a dedicated physical device for a bare metal machine. In all cases, these cards have relatively complicated setups.
For example, are "jumbo frames" good for you? What is important to see here, is that you might have a working system here,
but maybe you can shift to higher gear using the best configuration on IO cards and SANs. Its worth investigating.
Although all the database stuff sits on the SAN, don't forget that your database machine reads pages into it's cache,
and writes to transaction logs and database files all the time. Especially with large batch loads, IO can be very high.
Directly Attached Storage:
In general, here you have more control on how to implement filegroups over sets of spindles.
For performance reasons, one "filegroup" could even have it's files over different disks.
Also, you can seperate Tables and Indexes on seperate filegroups, which is a policy that enhances IO throughput.
But be carefull not to trade redundancy for performance.
32 bit/64 bit systems:
The 32 bit era is definitely over, since long by now. You can't use it anymore for serious SQL systems, except for playing around a bit.
Bare Metal / Virtual Machines:
My personal opinion, or my two cents:
- For medium intensive SQL Server installations it's OK to go for Virtual Machines (VMs).
One tremendous advantage over bare metal, are the good machine backup features, like for example just copying .vmdk files for backup of the machine state etc..
Another great HA option, is that a VM can move to another host, in case of problems, without downtime.
-For really high intensive, and very large environments, I'am still not impressed by hypervisor solutions.
But many other folks think differently, among them even highly reckognized SQL experts!
Today, Physical machines are totally "out", certainly with clouds and all modern virtualization techniques.
The "Metrics/Distance" of DB Server and Application Server:
Your databases are most often accessed by your users, through Application Servers.
Certainly with VM's, on different "hosts", the "metric" in vlans (networks) might be considerable, and that might
impact performance. I have seen a few times, that by moving a VM to another Host, performance was increased miracously.
If performance is indeed hindered by network latencies, you should for example see network related waits from the query in section 2.
Partition Alignment:
If you work in a larger organization, again it's likely your databases reside on central storage like SAN's.
But whatever your storage is, at a certain point at the "start", you format storage to get it usable under Windows Server systems.
So, you could have local storage, or have LUNs from a SAN, at some point you format them first before storing database files on them.
There are (at least) two points to consider: Partition Alignment (or sector alignment) and the allocation unit size.
The whole idea behind it, is to try to minimize the needed disk IO.
It is often recommended that you configure disk partitions to begin on sector boundaries that are divisible by 64K.
With a "diskpart" session, it would go like this (after selecting a disk):
DISKPART> create partition primary align=64
However, you must do research beforehand, or your see your SAN Admin first.
This is not very detailed information provided by me! Indeed, it's almost nothing. If this alignment stuff really would be new
to you, it would be a nice task for you to search the internet as well (keywords: partition alignment).
A very brief explanation on the "sector alignment" goes like this. Essentially, under NT systems we can have traditional MBR disks,
as well as the newer GPT disks. This differentiation is about on what for sort of "meta data" exists at the very first sectors on a disk.
For example, for GPT, it reserves LBA 0 (sector 0) to LBA 33 (sector 33) for metadata, leaving LBA 34 as the first usable sector for a true Partition
to contain data. This is not a handy starting point, if the implementation on the (remote) LUN or RAID array, uses a stripe set
of for example 64K, or 128K.
In such a case, "the boundaries don't match". The way the Local OS think it should write, does not fit optimally on the physical "disk" (LUN actually, which
behaves and looks like a "local" disk). It might result in more writes than is strictly neccessary, if the alignment what NT thinks it is,
would match the true implementation.
Actually, there are some storage implementations where such a reasoning does not apply at all.
At all times, It's best to get advice from a technical SAN specialist, from the SAN type that you are using.
As a general statement however: yes it makes sense to invest time on the best alignment, and generally it makes a difference.
For the logical "allocation unit" size, when formatting a disk, Microsoft advises to a use 64K unit size.
This is their advise, and they know their product best.
11. A few notes using the profiler.
Warning: below is very basic info. There is much more to say on the profiler than found in this note.Don't forget: it's a simple introduction.
Essentially it's tracing "tool" which allows you to "capture" the "pure" SQL statements issued to the database as well as many other events.
For statements, you will see that many facts are collected, as for example begin- and end time, the associated user account etc.. etc..
There are multiple objectives to use it, which are (among others):
- To create a "trace file" for (later) analysis. You can load the file at any time in the profiler and start analyzing.
- To create a "trace file" as a workload file for the "Database Tuning Advisor" (DTA).
of recommendations on indexes.
Before we go any further on the profiler, let's see what we have for tooling at the moment, and how to apply them:
- "Performance Monitor" to get hard performance data like for example "SQL Re-Compilations/sec" over a period of time etc.. See section 9.
- "Profiler" to get all statements issued over a period of time, with interresting facts as begin- and end time, the account, the application etc..
So, I hope the general scope of those two tools is a bit clear.
But there is something missing. How about information on the "access paths" or "execution plan"?
Don't we want to know if some SQL statement is using a "full tables scan", or hopefully the right indexes to speed up performance?
There are three answers to this:
(1): A profiler trace also contains some binary data, on basis of which a tool like DTA can make recommendations on indexes.
(2): Using Management Studio (SSMS), then using the Query Window, you can place there any query of interest,
and choose from the menu to show "the execution plan" as well. This really shows you the access paths and the "costs" involved.
(3:): Using the "system views", we can see "plan handles" which, using a bit of engineering of SQL, provides us with
very usefull information. We will get into that in section 11.
Now, let's go back to the "profiler".
The way I often do it, is often somewhat different compared to what you can find in oher notes. Usually, just a trace of 5 minutes or so
gives me plenty of info. This is so, since often I can ask a user to perform those actions needed (in whatever client is used, like
a webbased application, or Windows application etc..), and just do whatever it is, that leads to the slow response.
At that time, my trace is running too. Or, if it is a batch which is troublesome, It's easy to find out when the batch starts and subsequently
take a few traces during runtime.
You can either have "SQL Server Management Studio" (SSMS) installed on a workstation or "management Server" (recommended), or you
just run it on the Database Server itself. From the SSMS menu, choose "Tools" and select "SQL Server Profiler".
The Profiler starts, and as usual you need to authenticate (logon) to the Instance that you want to trace.
Next, the "trace properties" dialogbox appears. It's important to note that there are two "tabs" here, namely
"General" and "Events Selection". Right now, we are in the "General" tab. See the figure below.
Fig. 2. Trace properties dialogbox: "General" tab.

If you are new to the profiler, watch this dialogbox closely. You should give the trace a descriptive name, and you can choose
to save the data to a file, or to a table. This is an extremely fast intro, and we skip many details, but there are several reasons
why a "file" is often a better choiche (like e.g, it's more easy to copy the file or transport it, to another location etc..).
Choose a drive and directory with sufficient free space.
To give you an idea about the growth of (full) traces: on a very busy instance, a full trace can grow with something like 50MB per minute.
But don't worry. In my experience I always just let it run for a couple of minutes. But, in some situations you need to let a trace collect data
during nighttime. As you will soon will see, It's possible to let a trace focus on one particular process, or type of event,
which ofcourse strongly reduces the rate by which a trace will grow. This is filtering of data.
- So, it's possible to perform a full trace which records all activity over a set of selected events. Or,
- you can apply a filter that focusses of a specific account, sessionId, or application etc..
The means to "filter" (if you want to do that) comes after the "Trace properties dialogbox", so we need to finish that one first.
From figure 2, note that you can specify a "maximum filesize" for the trace. Always put an appropriate size there.
Note that you also can select "Enable trace stop time" at which point your trace stops collecting data. So, you can start a trace at say 1700h or so,
and go home, while you have configured the trace to automatically stop at, say, 20:00h.
Now, let's go to the "Events Selection" tab. See the figure below.
Fig. 3. Trace properties dialogbox: "Events Selection" tab.
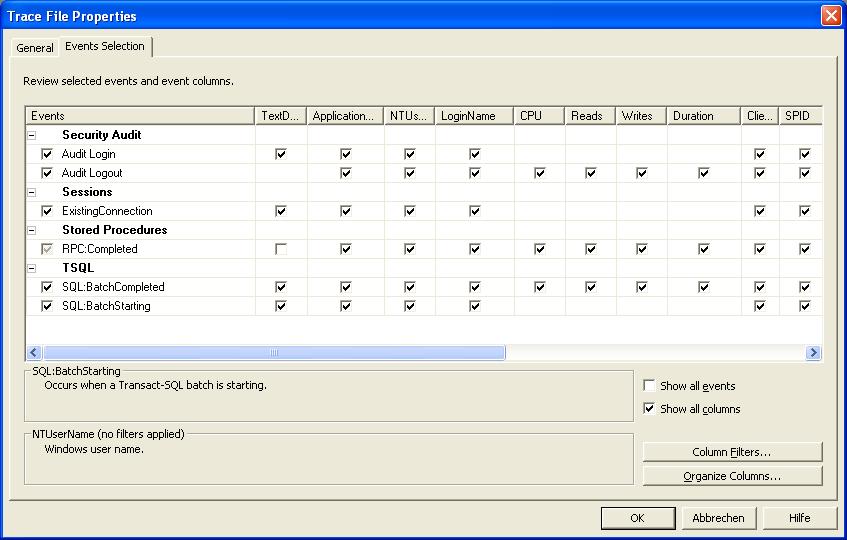
What you see here are "events" like SQL batch statements (ordinary SQL, which includes calls to stored procedures) which
here is called "SQL:BatchStarting" and "SQL:BatchCompleted". If you click on "Show all Events" then much more events
will show up, like "cursors", which you can trace too.
However, the "default" event selection, as it is, is sufficient for now. Ofcourse, you can always try the other events too.
Now, if you just take a look at one "event", say "SQL:BatchStarting", in the horizontal direction you will see "columns" which represents
the attributes of that event. These attributes are the "facts" like cpu, reads, the account which started the SQL etc.. etc..
Again, the default as shown now, is already pretty sufficient. If you click on "Show all Columns" then it turns out that
you can add many more "facts" (which are unselected now).
You see? You can easily spend a whole day or so, to explore all events and columns, to find out what could be best to trace for a certain
measurement. However, even if you would change "nothing", I think the default is pretty good (for me at least), since I am often just
interrested in just the SQL (plus stored procedures).
Filtering:
Now, if you would be happy with a certain selection of "events" and "columns" (the facts), then the measurement takes place over all sessions
which would trigger a certain event.
However, maybe you are only interrested in the events triggered by a certain login or maybe you are only interrested in the events
triggered by a certain application etc..
Then you could filter the data accordingly, which will result in much smaller trace files. Also, if you have applied a filter,
then all data in the trace is related to what you have filtered on and there will be less "noise" in the trace.
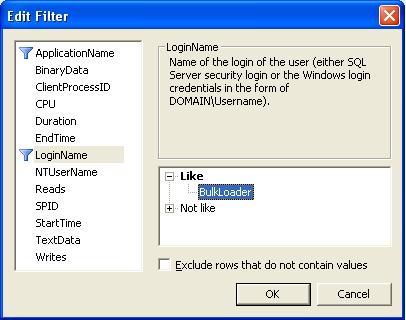
In Figure 3, you see the button called "Column Filters" and this allows you to select a particular process, or login
and many others to choose from. In figure 4, I have made a selection to filter on a certain login only.
Fig. 4. Choosing to filter (in this case: an "account")
Exercise:
I presume you have a SQL Server test instance somewhere. Use the profiler at this instance, and create a trace
using the default events and columns. Also, don't filter on anything. Let it run for a couple of minutes.
Now start SSMS, then open a Query Window, select some test database, and execute the statements below.
create table X
(
id int
)
GO
insert into X
values (1)
GO
Now stop the trace. In the profiler tool bar, you will see a small red square. If you click it, the trace stops.
You still have the trace loaded in the profiler. Now, from the main menu, click "Edit" and choose "Find".
Search on string "insert". Hopefully you will see the insert statement you did in table "X".
You can search a trace file on any string that might be of interrest, like the name of a stored procedure, the name of a table,
or terms like "INSERT", "UPDATE", "DELETE", "error" etc.. etc..
12. Some important System Views (DMV's).
- Some system views are "semi-static". They register al sorts of objects and properties of those objects.Only when something changes, the data is modified too.
Most folks call them the "catalog views" (like sys.databases, sys.serverprincipals etc..).
- Other views (the DMV's), of which many are related to statistics on performance, are "updated" continuously (sampling rate is very high).
Those are actually nothing else than variables in memory, where a "view" for exists (with the stanza defined in the "mssqlresources" database).
⇒ The Catalog Views:
As an example of a catalog view, "sys.databases" (a semi-static one) registers all main properties of all databases, like the name, dbid,
owner_sid, create_date, recovery model, collation, etc..
If you are really relatively new to SQL Server, study the output of:
select * from sys.databases
It's really great since you get so much usefull information from all db's at once.
As another example, if you want to know which accounts are registered for this instance, take a look in "sys.serverprincipals" (also a semi-static one).
Here you will find all accounts, their "sid's" etc..
So take a look at the output of:
select * from sys.server_principals
Some views are quite special: they register all objects included the system views themselves.
To illustrate that, suppose you want to find out which system views (and functions) can help
to find information on for example indexes, try the following query on "sys.all_objects". It will list all system views which can help
you finding details on indexes.
select name, type_desc from sys.all_objects where name like '%index%'
In the "where"clause, I specifically mentioned '%index%', which returns all system objects related to registering the indexes.
But suppose you were interested in "endpoints", then use " where name like '%endpoint%' " etc...
The "name" field in the output above, shows the name of the view that you can query. But usually, not only views will be listed. Generally you will
find "Stored Procedures" and "functions" too.
Many system views are "server scoped" meaning that they are registerin values Instance "wide", or values valid for all databases.
But they are query-able from any database. It really "looks" as if they are repeated in any database (see below).
Some others are "database scoped" and have only relevance to that particular database. In such a case, you really first must place your context
to the database of interest before querying that view.
Where are the system views stored?
The socalled "Resource database" (mssqlsystemresource) is a read-only database that contains the "plans" or "stanza's" of all system objects,
included the "system views". However, most "system views" also logically appear in the sys schema of every database.
A special class of system views, are the DMV's (see below). They have also the plan stored in "mssqlsystemresource", but in a live Server, the data is
is actually a set of variables in memory, which gets updated continuously (fully memory based).
This is so since most DMV's keep stats on performance related objects, like waits on resources etc..
However, there still are lots of other special system views, like those stored in the "master", or "msdb" database.
For example, the system views (system tables) in the "msdb" database, are related to registering of SQL Agent jobs, backups, replication etc..
⇒ The Dynamic Management Views (DMV's)
A special class of system views are the Dynamic Management Views (DMV's). They also have a "plan" on how they are structured
residing in mssqlsystemresource database, but once the Instance has booted, the "values in them" are actually a bunch of variables in memory.
That's why they are really "dynamic" and whatever they store, after a reboot it's gone (or empty).
Many of them keep statistics of the system and SQL Server, and most values are "cumulative" since the last boot of the Instance.
They often have a name that starts with "dm_", or, since they are in the sys schema too, their name actually starts with "sys.dm_"
These views are are really different from the catalog views, since the data is not physically stored on disk.
Here are a few DMV's, we already have used in the queries of sections 2 - 7:
sys.dm_os_schedulers
sys.dm_io_pending_io_requests
sys.dm_os_wait_stats
sys.dm_os_waiting_tasks
sys.dm_exec_sessions
sys.dm_exec_requests
For example, take a look at "sys.dm_os_wait_stats":
select * from dm_os_waiting_tasks
It keeps track, instance wide, of all "waits" for all known "wait types" (like for example "PageIOlatches" or "lock waits").
You cannot identify a certain cumulative "wait" for a certain wait type (a category), for a certain session. This system view just keep
cumulative counters for the whole Instance (since last boot).
As another example, it's also very instructive to take a look at the contents of "sys.dm_exec_session" and "sys.dm_exec_requests".
Both are related to user sessions and register many interesting facts around those sessions.
select * from sys.dm_exec_sessions
select * from sys.dm_exec_requests
- "Sys.dm_exec_session" shows facts on all sessions (identified by their session_id's). It's more oriented around session facts like
the login_time, the account associated with the session_id, from which host the session runs, memory usage, last succesfull/unsuccesfull logons etc..
- "Sys.dm_exec_requests" shows facts on all sessions too. It's more oriented around session requests like
the wait's, the command associated with the session_id, the database it is working in, the "sql handle"and "plan handle" of the last issued SQL statement etc..
Those last two will be discussed later.
Let's take a look again at a query we have seen before in section 7. Here we join "sys.dm_exec_sessions" and "sys.dm_exec_requests" on a field
which they have in common, namely the "session_id".
SELECT
s.login_name, s.nt_user_name,
r.session_id AS BLOCKED_SESSION_ID,
r.blocking_session_id AS BLOCKING_SESSION_ID,
s.program_name,
r.start_time,r.status,r.command,database_id,
r.wait_type,r.open_transaction_count,r.percent_complete,r.cpu_time,r.reads,r.writes,r.deadlock_priority
from sys.dm_exec_sessions s, sys.dm_exec_requests r
where s.session_id=r.session_id AND blocking_session_id > 0
This is how it often goes. Many DMV's have interresting fields by themselves, but often you want several fields of two
or more DMV's, to get a more complete picture.
Here are some DMV's and functions (later more on that), which are important in any performance analysis.
For the views in the table below, you might want to try "select * from viewname" to see what information can be obtained.
Table 1:
| view/function | DMV name |
| view (Instance analysis) | sys.dm_os_wait_stats |
| view (Instance analysis) | sys.dm_os_waiting_tasks |
| view (Instance analysis) | sys.dm_os_schedulers |
| view (Instance analysis) | sys.dm_io_pending_io_requests |
| view (Session/Query analysis) | sys.dm_exec_sessions |
| view (Session/Query analysis) | sys.dm_exec_requests |
| view (Session/Query analysis) | sys.dm_exec_connections |
| view (Session/Query analysis) | sys.dm_exec_query_stats |
| view (Session/Query analysis) | sys.dm_exec_cached_plans |
| view (Session/Query analysis) | sys.dm_tran_session_transactions |
| view (Session/Query analysis) | sys.dm_tran_active_transactions |
| function (Session/Query analysis) | sys.dm_exec_sql_text(sql_handle) |
| function (Session/Query analysis) | sys.dm_exec_query_plan(plan_handle) |
| view (index analysis) | sys.dm_db_index_usage_stats |
| view (index analysis) | sys.dm_db_missing_index_details |
| view (index analysis) | sysindexes |
| function (index analysis) | sys.dm_db_index_physical_stats() |
| function (index analysis) | sys.dm_db_index_operational_stats() |
⇒ Dynamic Management Functions (DMF's):
From table 1 you can see that not only "Dynamic Management Views" (DMV's) are of interrest,
but "Dynamic Management Functions" (DMF's) as well.
Both views and functions are "code�, so they actually are not very dislike from each other.
And, most fuctions just operate on the DMV's.
Also, they thus provide a "window" on counters/variables in memory, and those counters are most often related to performance stats.
Although both views and functions are "code", there is one important difference. A function generally may take one ore more
arguments when you call it, like in "function_name(argument)".
Since there are occasions where you are only interested in (for example) one database, or one index or some other entity,
a function that takes such an entity as an argument, would be perfect. That's why Microsoft not only created DMV's, but DMF's as well.
We will see how the DMF's work in the next section where we discuss indexes.
13. A few words on Index tuning:
13.1 General Index information:
There are two main types of indexes:- Non-clustered indexes are the "normal" indexes, like those availabe in all other database engines. These are seperate objects from the table,
and uses separate database pages. A table can have one or more non-clustered indexes. A non-clustered index is defined on one
or more columns of the table. A non-clustered index "looks" like a mini version of the table. It has a copy of the column (or columns) like
the parent table has, and an equal number of rows that the parent table has. At each row of the index, we find a certain value of the column
and a "pointer" which "points" to the corresponding database page in the parent table.
This explains why using an index, speeds up the search of values of the parent table, since actually the index is used in the search,
and the pointers are then used to get the actual rows of the parent table. - A table can have only one clustered index defined. A clustered index (like a non-clustered index), is defined on one or more columns
of the parent table. But when the clustered index is created, it will physically sort the rows of the parent table
on the choosen columns. Actually, a clustered index will become the table itself ! (more precisely: the leaf level pages
of the index are the same as the table pages.
So, a clustered index is not an external object. The table pages are the index pages.
Since you can sort the rows of a table, based on one or more column(s), only once it follows that a table can have only one clustered index.
the rows in the table itself were not sorted on the basis of one or more keys (columns.)
- A table with a clustered index is not called a "heap" anymore. The rows of the table are physically sorted on the choosen columns
- A table can have only one clustered index defined on it.
- A table can have one or more non-clustered indexes defined on it. A non-clustered index is just an external object.
- A table can have a clustered index, and one or more non-clustered index, at the same time, since the non-clustered indexes
are external objects, and do not physically sort the parent table.
In general, index tuning is not at all a trivial task. Some pointers:
⇒ Most tables will have a "primary key" defined. A primary key, garantees unique records. If indeed defined, a clustered index
will be created automatically.
But, a table without a primary key, can still have a clustered index, if you create one. It does not have to be defined
on a column with unique values. So, having a clustered index, is not synonymous to having unique values in some column.
⇒ A column with a "high selectivity" (meaning many unique values like a customer id), is a good candidate for any index,
but that's especially true for a clustered index, since the parent table will be sorted on that column.
⇒ At any INSERT, UPDATE and DELETE statement, not only the parent table gets updated, but all indexes as well !
Since an index should reflect the current state of affairs, all modifying statements on the table, will alter the indexes too.
Consequently, it's important to have a well-balanced set of indexes: to have missing indexes is bad, but so is having too much indexes.
⇒ A missing index on a column (or columns) which are often queried, will hit performance.
⇒ Having too many indexes will hurt performance too, since all indexes needs to be updated as well at any modifying statement on the parent table.
⇒ An "archetype" of a SELECT query is a bit like this: "SELECT columns FROM table WHERE criteria".
Especially the column(s) mentioned in the WHERE clause, can be interresting candidates to create an index on.
⇒ A filegroup is a logical concept, which uses one or more physical files. Those files can be on the same
or different disks. You can create a table on a certain filegroup. You can create the associated non-clustered indexes on a
different filegroup. So, if you want, and if circumstances allow you, you can seperate disk IO, that is,
seperate table IO to be on a certain filegroup (certain disk or disks) and index IO to be on another filegroup (other disk or set of disks).
Remark:
Since a clustered index is the same as the table itself, seperating IO of the clustered index and the table, does not apply.
However, you can still have a filegroup with multiple files where the table/clustered index lives on, thereby still achieving parallel IO.
This is especially true if those files resides on different disks.
Remark:
In general, for a Database, try to place the tables and the indexes on different filegroups (different spindels/disks).
In general, for a larger table, place the "table=clustered index" (if that index exist) on filegroup A, and place the non-clustered indexes on filegroup B.
In general, for a very large table, consider partitioning, that is, parts of the table (or index) stored on a number of filegroups.
13.2 Some helpfull queries:
⇒ 1. Using the legacy "sysobjects" and "sysindexes" views:One of the best queries for index analysis, was available since SQLServer 7. The following query really is great. It shows you
the tables, and all associated indexes defined on the tables, as well as other info like the number of rows.
In the Query Window of SSMS, you should choose the database of interest first, before you run this query.
SELECT
substring(sysobjects.name,1,50) AS TABLENAME,
substring(sysindexes.name,1,50) AS INDEXNAME,
sysobjects.id, sysindexes.indid, sysindexes.groupid,sysindexes.rows
FROM sysobjects, sysindexes
WHERE sysobjects.id=sysindexes.id
ORDER BY sysindexes.rows desc
sample output..
TABLENAME.......INDEXNAME........id..........indid....groupid.....rows
---------.......---------........---------...-----....-------.....----
CUSTOMERS.......pk_cust_id.......375751725...1........1...........54221
CUSTOMERS.......indx_cust_1......375751725...2........1...........54221
EMPLOYEE........pk_emp_id........695752863...1........1...........40022
ORDERS..........NULL.............701575400...0........1...........33991
ORDERS..........indx_orders_1....701575400...2........1...........33991
articles........NULL.............734622211...0........1...........26231
articles........indx_articles_1..734622211...2........1...........26231
articles........indx_articles_2..734622211...3........1...........26231
articles........indx_articles_3..734622211...4........1...........26231
etc..
If you run this in a database with large tables and indexes, you will immediately see which large objects might be
candidates of further investigation.
For example, say you find some tables having over 1700 million rows, it's evident that having optimized indexes
is quite crucial. That is, if these tables are indeed used often. But that's quite likely if we see their sizes.
It's obvious, that if a such a large table (plus indexes) would be present in a database, but it's not used, then it has
not much impact on performance.
Note that in some case, some tables are just used for "logging" or "auditing", and these can grow rather quickly.
If you have those, you can investigate whether the bulk of data can just be archived to a file or something, keeping the
current table(s) modest in size.
But, for modern large DWH's (and even large OLTP systems), tables having over, say, 1700 million rows is not uncommon.
Although I think these are still monster tables, and it might be hard to perform proper maintenance on them.
Note: Large objects as these, might be candidates for partitioning as we will discuss in section 14.
Be carefull though. Even if you have a small table, without proper indexes, it can hurt performance immensly.
Suppose you have a table with only 60000 rows. This is ridiciously small indeed! Yes, but if this table is heavily used by some
application, and SQL Server performs a full scan all the time, instead of using a proper index, performance is really hit.
Note that the query shows you the "object id's" of the tables, as well as the "index id's" of the associated indexes.
Microsoft defined a number of rules with respect to these id's. Here is how you must "interpret" those id's.
ObjectId:
Each object (like a table) in a database has a unique "ObjectId". In the output above, it's the "id" column, and it represents the
object id of the table. For example, the table "CUSTOMERS" has an objectId of "375751725".
IndexId:
Each index of a certain table has an "indexId", like 1,2,3 etc.. But that counts "per table", so an indexid is not unique
on the database level, but instead, per table. So, suppose "TableA" has 3 non-clustered indexes, then the indexId's
are 2,3,4. Next, suppose "TableB" has 4 non-clustered indexes, then those IndexId's are 2,3,4,5. So, these Id's are relative to the table.
If a table has a clustered index, then that index will have an "IndexId" of "1". So, in output as of the query above,
any table with a "clustered index" is immediately identified if you find an IndexId of value "1".
If a table has no clustered index, then the table is a "heap". Ofcourse, it might have non-clustered indexes defined.
But the table still is a heap, and in such a case, the IndexId is "0", and it actually represents the table itself. So, the indexname is "NULL".
If the table would indeed have nonclustered indexes, then their indexid's start as of indexid=2, since IndexId=1 is reserved
for a clustered index (which this table does not have).
So:
The output of the query above tells you:
- If you see an IndexId of 0, then there exists no clustered index for that table, and the table is an (unsorted) heap.
- If you see an IndexId of 1, then that's the IndexId of the clustered index, which is equal to the table itself.
- All non-clustered indexes of a table have indexId's which start of value 2 (like 2,3,4 etc..).
⇒ 2. Using the "sys.dm_db_index_usage_stats" DMV:
This DMV provides us with data on "user_seeks", "user_scans", "user_updates" and much more, on all indexes in all databases.
So, it might help to "determine" the effectiveness of indexes.
But there might exists catches with this one.
- It's probably tempting to think, that if the "updates" on an index are much higher than the "seeks"+"scans", then the index
is not much used, and is probably not very effective. Maybe it's better to get rid of it.
As you may have expected, low values for "seeks" indicate that an index does not work well. - Contrary, if the "seeks"+"scans" are much higher than the "updates", it's an indication that the index is properly used,
and it's likely that we deal with an effective index here.
Although the info from querying "sys.dm_db_index_usage_stats" is very usefull, it's certainly better not to let it be your single
source of information.
As allways, see it as just one of the "observables" that helps in establishing the grand picture.
Warning:
Never drop an index "just like that", even if it seems to be useless one, unless you are confident it can't hurt to drop it.
For example, maybe some important "batch", running only once a week at night, refers to that particular index, and if that index is gone,
the batchrun may give you unpleasant results.
So, see it as a change which generally should be tested first.
To "see what's in it" try the following statement:
SELECT * FROM sys.dm_db_index_usage_stats
As you can see, the output is not so very friendly. You see "database id's", "object id's", "index id's",
and the values you are interrested in like user_seeks, user_scans, user_lookups, user_updates, last_user_seek, last_user_scan, last_user_lookup.
There are more columns in the view like "system_updates", but the "system" fields are for system operations like automatic statistics and the like.
So, to make the output more friendly, we need to join this DMV with other systemviews like sysindexes.
Here is a usable query for obtaining statistics on seeks, scans, and updates, for all your indexes:
SELECT object_schema_name(indexes.object_id) + '.' + object_name(indexes.object_id) as objectName,
indexes.name, + indexes.type_desc,
us.user_seeks, us.user_scans, us.user_lookups, us.user_updates
FROM sys.indexes left outer join sys.dm_db_index_usage_stats us
on indexes.object_id = us.object_id
and indexes.index_id = us.index_id
and us.database_id = db_id()
order by us.user_seeks + us.user_scans + us.user_lookups desc
I have used "sys.dm_db_index_usage_stats" in many databases by now, also lots of databases of well-known manufacturers.
It's almost unbelievable how often indexes are shown to be ineffective, if you believe the stats in "sys.dm_db_index_usage_stats".
Also, I have some "reservations". Suppose you find an index which seems not to be used much (updates >> seeks+scans).
Well, maybe the index is principally not bad, but maybe "code" uses the wrong "hints" and that could explain why the index is not used.
My two cents are: if you just regard it as "just one of the tools" in your arsenal, then I guess it's OK.
⇒ 3. Using the "sys.dm_db_index_physical_stats" function:
This function (DMF) returns fragmentation information on objects. Usually, a function takes one or more arguments,
like in function_name(arg1, arg2,..) This one can take 5 arguments. However, some, or all of them, might be "NULL".
The more arguments you specify as "not null" (so you put in a real value), the more you zoom in to a set of objects, or utimately, one index.
The funtion with all arguments looks like this:
sys.dm_db_index_physical_stats(database_id, object_id, index_id, partition_number, mode)
But you can leave one to all arguments as "NULL". So, for example, if partitioning is not used, leave it at "NULL".
What "fragmentation" actually means, and how to solve it, is the subject of section 13.3.
You probably often are interrested in the fragmentation level of all indexes in a certain database, or you want
to investigate a specific index.
In these cases, below is shown how you could use the "sys.dm_db_index_physical_stats" function.
If you know the "database id" (dbid), you can use that number. Otherwise just fill in the database name of your choice,
and the function "db_id(database_name)" will find this id for you.
SELECT object_name(object_id), index_id, index_type_desc, index_depth, avg_fragmentation_in_percent, avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID('YOUR_DATABASE_NAME'), null,null,null,'DETAILED')
WHERE index_id<>0
SELECT object_name(object_id), index_id, avg_fragmentation_in_percent, avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID('YOUR_DATABASE_NAME'),OBJECT_ID('YOUR_TABLE_NAME'),INDEX_ID,null,'DETAILED')
The first query, where you want to see the state of all indexes in a certain database, can take quite some time and resources
in a larger and active database. So, try it first in a test environment.
13.3 Creating, Reorganizing and Rebuilding Indexes:
⇒ Examples of creating an index:-Non-clustered:
CREATE NONCLUSTERED INDEX indx_employee_empname ON EMPLOYEE(EMP_NAME)
CREATE NONCLUSTERED INDEX indx_employee_emp_cp ON EMPLOYEE(CITY, POSTALCODE)
-Clustered:
CREATE CLUSTERED INDEX indx_employee_empid ON EMPLOYEE(EMPID)
-Strongly Simplified General syntax:
CREATE [CLUSTERED | NONCLUSTERED] INDEX
⇒ Reorganizing and Rebuilding an index:
What a "large table" is (and thus having large indexes too), just depends on what you are used to. Some find 50 million rows large,
but actually that's quite small for many (or most) other DBA's.
Quite a few "real-life" databases, have tables with over 5000 million rows, and even considerable larger.
And... even real monsters exists too (>100G rows).
Anyway: Reorganizing or Rebuilding a truly small table (say 100000 rows) does not take much time. Maybe within a few seconds or so.
However, rebuilding indexes on a large table may take a very long time. The larger the number of rows, the more difficult it gets.
For very large tables, you need partitioning, and handle partitions one at the time.
To get an idea:
- on a "reasonable" Win2K8/SQL2008 machine, with reasonable IO and other resources, then rebuilding a 50 million row table
with, say, 20 columns with standard datatypes, a clustered index and 5 nonclustered indexes, should certainly not take more than 20 minutes.
- on a "reasonable" Win2K8/SQL2008 machine, with reasonable IO and other resources, then rebuilding a (non-partitioned) 5000 million row table
might take very long, or, more likely, is a nightmare.
=> Index Rebuild: Too bad that with the Standard Edition, a Rebuild cannot be done "online". This means that you can always try to rebuild an index,
if there is no spid (useraccess) is accessing some row at the same time the rebuild does. So, generally, there are potentially high chanches on "locks".
If you are sure that some table is not accessed by some user, the rebuild will go fine.
The Enterprise Edition provides for the "Online" clause, which will rebuild the index while tableaccess by users is going on.
However, with large tables and high user concurrency, I have seen many "locks" all the time.
=> Index Reorganize: A Reorganize can always be done online.
REORGANIZE:
ALTER INDEX index_name ON table_name REORGANIZE -- just reorganize one index on a certain table
ALTER INDEX ALL ON table_name REORGANIZE -- reorganize all indexes for table_name
REBUILD:
ALTER INDEX index_name ON table_name REBUILD -- just rebuild one index on a certain table
ALTER INDEX ALL ON table_name REBUILD -- rebuild all indexes for table_name
ALTER INDEX ALL ON table_name
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON)
Both the reorganize and rebuild statements can use a lot of additional "clauses" like FILLFACTOR and many more.
In essence, a Reorganize uses the existing Index, and logically reorder the pages and refills them again.
In essence, a Rebuild is like dropping the index and completely rebuild it again.
A rebuild is very effective, if you can afford it.
Dynamic statements to generate a script for all indexes for all tables:
Here are two simple loosp to generate the statements for a rebuild for all indexes for all tables in a Database:
One script uses the modern "ALTER TABLE.." statement, while the other use the older "DBCC DBREINDEX()" statement.
So, the endresults are listings of statements.
-- script 1:
set nocount on
DECLARE @TableName varchar(255)
DECLARE MyCursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_type = 'base table'
OPEN MyCursor
FETCH NEXT FROM MyCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'ALTER INDEX ALL ON '+@TableName+' REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON)'
FETCH NEXT FROM MYCursor INTO @TableName
END
CLOSE MyCursor
DEALLOCATE MyCursor
-- script 2:
set nocount on
DECLARE @TableName varchar(255)
DECLARE MyCursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_type = 'base table'
OPEN MyCursor
FETCH NEXT FROM MyCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'DBCC DBREINDEX('+@TableName+','+''''',90)'
FETCH NEXT FROM MYCursor INTO @TableName
END
CLOSE MyCursor
DEALLOCATE MyCursor
Note: if the indexes are in some "schema" (owner) other than dbo, you can simply use notepad with the generated statements,
and replace text like 'ALL ON ' with 'ALL ON owner.'
Ofcourse, it's much smarter to use a second variable in such script, and get the owner as well from the "information_schema.tables" view.
This might be a nice exercise.
14. Some notes on Database Design and Instance options:
Here are some short general recommendations for the Physical Database Design, and a few words on Instance options.It's all rather trivial I am afraid, but I just have to mention it in a note like this one.
However, viewed from the latest technology, all listed below might strike you as "old-fashioned stuff".
That's true, but there is still quite some value in the arguments listed below.
14.1 Physical Database design::
=> Simple Design Considerations:For any valuable database, you must always seperate the actual database files, from the transaction logfiles,
and indeed, put TEMPDB at still another location.
That is: place the database files, the transactionlogfiles, and TEMPDB, on seperate disks (or LUNs).
Now, these "disks" actually needs to be seperate "spindles" (true disks), otherwise there will be not much value
in this exercise (with respect to performance gains).
The whole idea behind this is ofcourse to seperate the disk IO to different disksystems, in order to increase the performance.
For example, the access to the database files (containing tables and indexes) is of a more "random" nature, if we would
compare it to the more "serialized" access to the transaction log.
So, suppose you would have the LUNs/disks K:, L:, and T:, then you could create the following folders:
| Filesytem and folder: | Contains: |
| K:\SQLData | storage of the database files |
| L:\SQLLog | storage of the transaction log files |
| T:\TEMPdb | contains the TEMPDB |
Now, if your Instance handles multiple databases, then the files of all those databases will be stored on "K:" and "L:".
In case that this Instance has a considerable number of databases, then maybe too much contention exists on "K:" and "L:"..
In such a case, you might consider additional LUNs/disks, to store a set of databases on those LUNs as well (in order to keep the
performance acceptable).
If you have something like 20 (or so) "moderate" databases on one Instance, and these are OLTP like, you might get away with such a setup
as described above.
However, some large databases in larger organizations have a very high transaction rate. In such a case, often the Instance
is fully dedicated for that database only.
Then filesystems (LUNs) might then be arranged as in this example:
F:, G:, H:, I:, J:, K:, L: for database files of that database
M:, N:, O:, P:, Q: for the transactionlog files of that database
R:, S:, T: for storage of TEMPDB (if IO on TEMPDB is high too)
However, such a layout is indeed a bit exceptional, unless IO throughput really requires it.
=> Seperating storage of tables and indexes:
Since it is advisable to seperate tables from indexes, on seperate filegroups, you might put that into a reality as well.
If those table and index filegroups are on seperate LUNs/disks, you have an additional level of IO seperation.
As you know, a clustered index corresponds to the (leaf) pages of the table itself, so, in practical terms, "they are the same".
The non-clustered indexes, which might have been defined on a table, are objects by themselves.
So, you might consider a database file layout as follows:
| Filesytem and folder: | Contains: |
| K:\SQLData | storage of database files containing tables |
| L:\SQLIndex | storage of database files containing clustered indexes (other tables) |
| M:\SQLIndex | storage of database files containing non-clustered indexes |
| N:\SQLLog | storage of transaction log files |
| T:\TEMPdb | contains the TEMPDB files |
So, suppose you had the followind DB create script:
CREATE DATABASE Sales
ON
PRIMARY -- primary filegroup
(NAME=SalesPrimary,
FILENAME='K:\SQLData\sales.mdf',
SIZE=128MB,
MAXSIZE=200,
FILEGROWTH=32),
FILEGROUP SalesData
(NAME=TestData01,
FILENAME='K:\SQLData\salesdata01.ndf',
SIZE=8192MB,
MAXSIZE=16384,
FILEGROWTH=32),
FILEGROUP SalesIndexClus
(NAME=TestIndexClus01,
FILENAME='L:\SQLIndex\salesindexclus01.ndf',
SIZE=8192MB,
MAXSIZE=16384,
FILEGROWTH=32),
FILEGROUP SalesIndex
(NAME=TestIndex01,
FILENAME='M:\SQLIndex\salesindex01.ndf',
SIZE=8192MB,
MAXSIZE=16384,
FILEGROWTH=32)
LOG ON
(NAME=SalesLog,
FILENAME='N:\SQLLog\saleslog01.ldf',
SIZE=4096MB,
MAXSIZE=16384,
FILEGROWTH=32)
GO
ALTER DATABASE Sales
MODIFY FILEGROUP SalesData DEFAULT; -- avoid placing objects on the primary filegroup
GO
Since we have identifyable filegroups now, we can place (or move) tables and indexes on (to) the desired filegroups, like for example:
CREATE TABLE EMPLOYEE
(
emp_id int not null,
emp_name varchar(32) not null,
emp_city varchar(32)
)
ON SalesData
GO
CREATE NONCLUSTERED INDEX indx_employee_empname ON EMPLOYEE(EMP_NAME)
ON SalesIndex
GO
And, in former sections, we already have seen how to move tables, and indexes, to another filegroup.
14.2 Partitioning Tables and/or Indexes:
For very large tables and indexes, it can be beneficial to implement "partitioning".Basically, it means that a table has a (or more) suitable column(s) like for example "year", and we "store" the rows of the table
on different and seperate filegroups on the basis of the particular "year" in such a row.
This way, you can spread IO to different filegroups, and/or might even consider some filegroups like to be "archived" (like if the year
in the record is earlier than a certain year.
For more information, you might want to see this note.
14.3 Encryption, auditing:
Encrypting the data of a database, will certainly have a negative impact on performance. No doubt you think that's a rather trivial statement.However, your company policy might require it.
As another trivial statement: auditing events, negatively impact performance too.
I personally think that it's not really useful to "log" in detail which accounts performed INSERTS, UPDATES an DELETES on all tables.
Good security implementations should already take care of which roles and accounts may alter objects, which makes such a form of auditing useless.
Contrary, it is usefull to audit (truly important) security events like changes in database- and server roles and the like.
Advice: only implement a sane audit policy, without useless overhead.
15. DBCC memory viewing and manipulation commands:
Some DBCC commands let you view in detail where the SQL memory is used for. You can also "manipulate" some "caches",like clearing the cache storing the SQL plans, or clearing the cache assiociated with TEMPDB or another database.
I have placed it in a seperate short document. If you like to try it, then use this note.
This concludes this simple note. It was oriented on physical stuff, waits, indexes etc.., but not on "queries" themselves.
If you want to see a simple note on "Query design and tuning", you might want to try this note.